
Kuyta: Welcome back everyone! For today’s blog post I will be talking about AI and machine learning again. But this time, I will show the machine learning models for sound generation, especially music creation. I, myself, am very keen on music. I love to listen to music. However, my listening genre is mostly different from others (just look at my top ten played pieces). I love classical and electronic music, and I am not a fan of music that has lyrics. I also tried to make music.
(Sir Potata: He’s an elitist when it comes to music. STAY AWAY. But check out his music. It’s pretty cool.)
Kuyta: So that’s why I wanted to write this post on music creation. I want to show everyone AI’s music creation.
How does Music Generating Models Work?
In my other post, we learned how machine learning models actually work. Sound-generating models are not an exception to what I mentioned. Basically, we gather music files (like the ones in this dataset) that have many different styles, like classical, electronic, hip-hop, rock, metal, etc. We also should know every single music file’s metadata, like its lyrics, type, genre, and artist who made the music. After that, we can train the machine learning model on the gathered dataset. Some music-generating models will also have a language model attached to them. With the language model, we can write anything that we want to be made, and the music-generating model can make it.
Cool Machine Learning Models for Music Creation
MusicLM
First music generating model that I came across was Google Research Team’s MusicLM. This model is actually one of the newest ones, published on January 26. This model can create a music file from a text description of the music wanted. Let’s look at two of the 30-second pieces that the model created.
As seen from the second example, the model can replicate human singing and humming. While it cannot replicate real lyrics, it can still give the impression that it is saying something in a different language.
The model can also replicate a melody given to it and create a new music from the given melody.
One of the interesting things that this model can do is it can create a whole piece from different text descriptions. It basically can transition from anything to anything without a problem.
Overall, this model is very capable of generating music, and I really like the style that it creates. I should also mention that there isn’t a place where you can try this model for yourself. I took the audio from the paper itself, and there are many more examples of what this model can do in it.
JukeBox
Jukebox was made by the infamous OpenAI. By capturing over 1.2 million songs and their lyrics over the internet, they created this model to generate a song by the given genre, artist, and style. Over the 7000 songs that they created, I chose some of the best ones from the list, and here they are.
BoomyAI
Well… This AI is actually incredible. I am very impressed with it. You just create an account on the platform and start creating music of your own. Basically, you just select your music type, instruments and sounds. Then, you click “create” and voila. You now have created a song. I played with this model for some time and I created many songs. Here are some of my creations.
Beat Blender
Beat Blender is an experiment made by Google engineers to create music with simple beats. From the main beat that you create, the model generates more with four different main styles called “4 corners”.
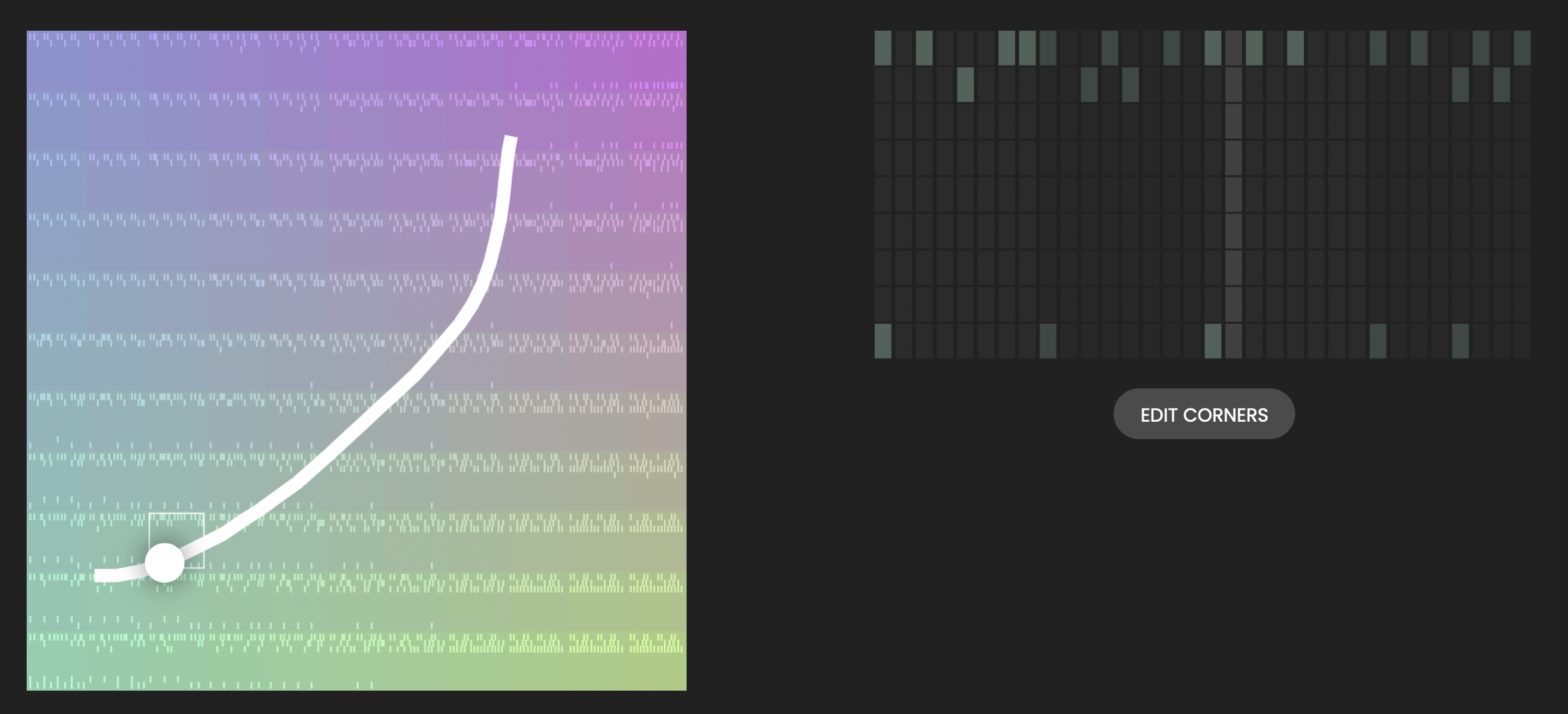
While the model is not that advanced compared to other ones we analysed, the system that they designed is very simple and useful. Anyone with an interest in music creation can try this model. People who are also interested in machine learning can try to learn how the system actually works.
Runn and Sornting
RUNN and Sornting were made by a single software engineer. The games are actually very different from what we mentioned above. These are not mainly for the music generation. They are actual games. Both of them use machine learning models to generate music, and the game revolves around that generated piece.
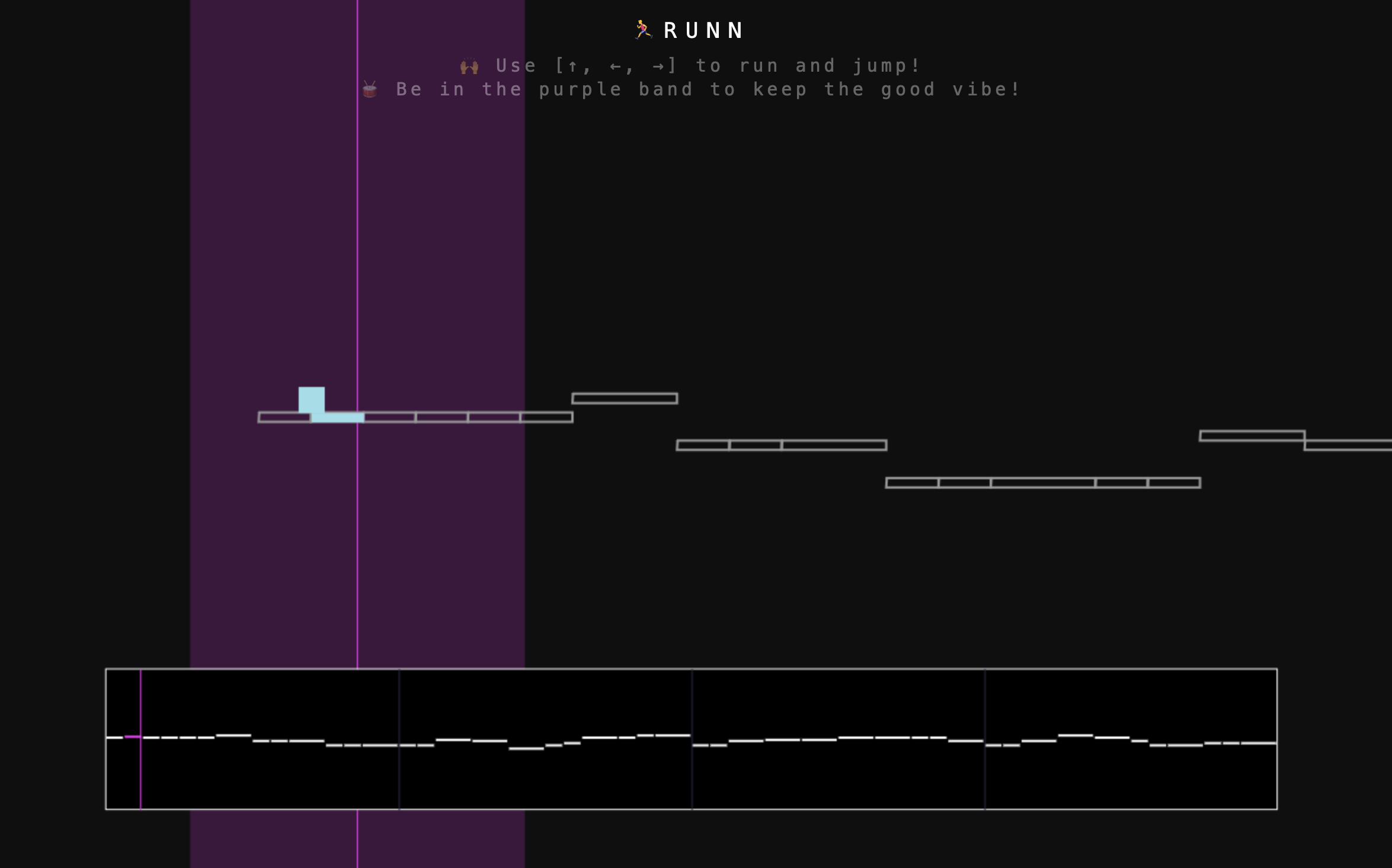
RUNN has the infinite-runner type but it is actually not infinite? For me, this game was very, and I mean very, hard to play as a single person. You might actually beat (haha, a pun because the game is about beats) it with two players.
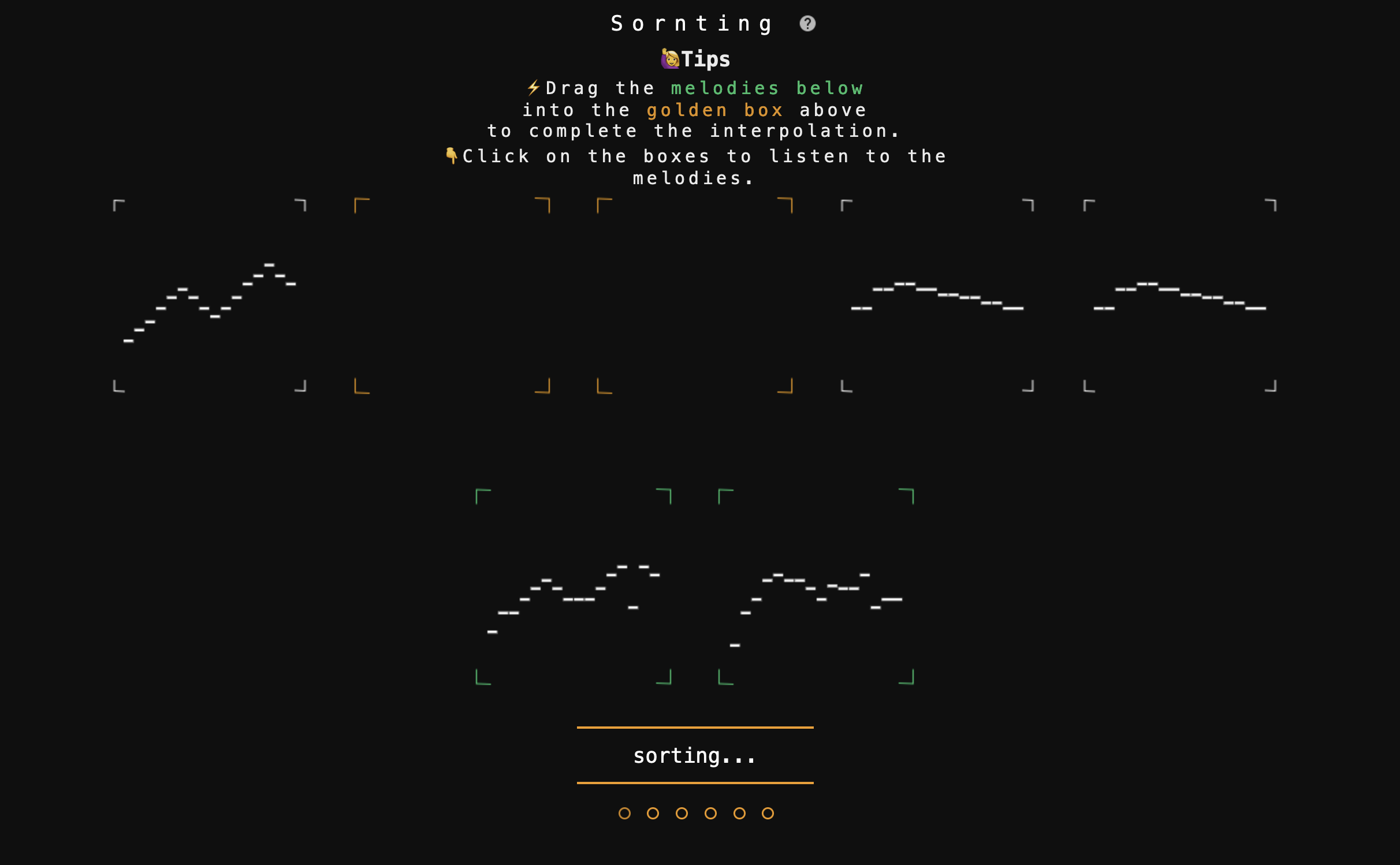
Sornting is a game about placing the missing parts of a song. Unlike the other one, this one is very enjoyable because every time you play, the pieces are different from the last time (because the model creates new music every time). I actually beat the game with zero mistakes. 😎
Ethics of Music Generating Models
It is not all butterflies and rainbows in the music generation, however. Everything that I mentioned is really great, and I actually wonder what will happen next. But I am also concerned about the ethics of creating these models. As mentioned, OpenAI used over 1.2 million songs to train their model, and MusicLM used over 280,000 hours of music to train their model. A high percentage of those pieces were probably used without the consent of the actual creators of the music. Or even worse, they still do not know that their songs were used to train AI. This, firstly, violates the copyrights of the owner. Secondly, this usage is very harmful to the creator, as people can type something like “Taylor Swift style” into the text prompt and get something that has the style of Taylor Swift.
I also fear that the increasing usage of these kinds of machine learning technologies might make newcomers to music composition sad and break their dreams. As seen from the examples by BoomyAI, the AI-generated music is really hard to differentiate from the real ones. This can have big implications in the future if this situation is not dealt with.

(Oh btw, I copied the starting sentence from Hikaru. If you know you know.)
