
Kuyta: Hello to everyone! While Sir Potata is busy with some nerdy stuff, I thought I could write a post on how AI works. So here we go!
Now that we know about AI’s definition and history, we can talk about how it works. In our other posts, we mentioned how the subfield of artificial intelligence known as machine learning, is widely used in today’s world, and in this post, we will discuss how machine learning models work.
As a recap, if you don’t remember our last post, machine learning is the capability of a machine to imitate intelligent human behaviour. Artificial intelligence systems (machine learning models) are used to perform complex tasks in a way that is similar to how humans solve problems.
Machine learning is one way to use AI. It was defined in the 1950s by AI pioneer Arthur Samuel as “the field of study that gives computers the ability to learn without explicitly being programmed.” This definition is very true today and it is important to understand how machine learning algorithms work. Basically, writing a program that a machine can follow is very time-consuming or straight up impossible. Like, training a computer to recognize human faces. While it is possible to code direct instructions that a machine can follow, it is very very difficult and time-consuming. Here, machine learning takes the approach of letting computers learn to program themselves through experience and trial-and-error.
Now that we know how and why machine learning algorithms are actually and literally learning, we can now get into the nitty-gritty of how machines learn.
Well, as with everything, it all starts with some big data—numbers, photos, or text, like bank transactions, pictures of people, repair records, time series data from sensors, or sales reports. All of this data is gathered and intricately prepared to be used as training data, or the information the machine learning model will be trained on. The more data, the higher the accuracy, and therefore the better the program.
After collecting the big data, which is honestly the hard part because collecting quality data is very, very hard (speaking from experience), programmers choose a machine learning model to use, supply the data, and let the computer model train itself to find patterns or make predictions. This training period can take days or even weeks if your computer is slow, but if you are Google, you can train big machine learning models in seconds (I am totally not jealous). Over time, the programmer can also tweak the model, including changing its parameters, to help push it towards greater accuracy and better results. Also, some data is held out from the training data to be used as evaluation data, which tests how accurate the machine learning model is when it is shown new data.
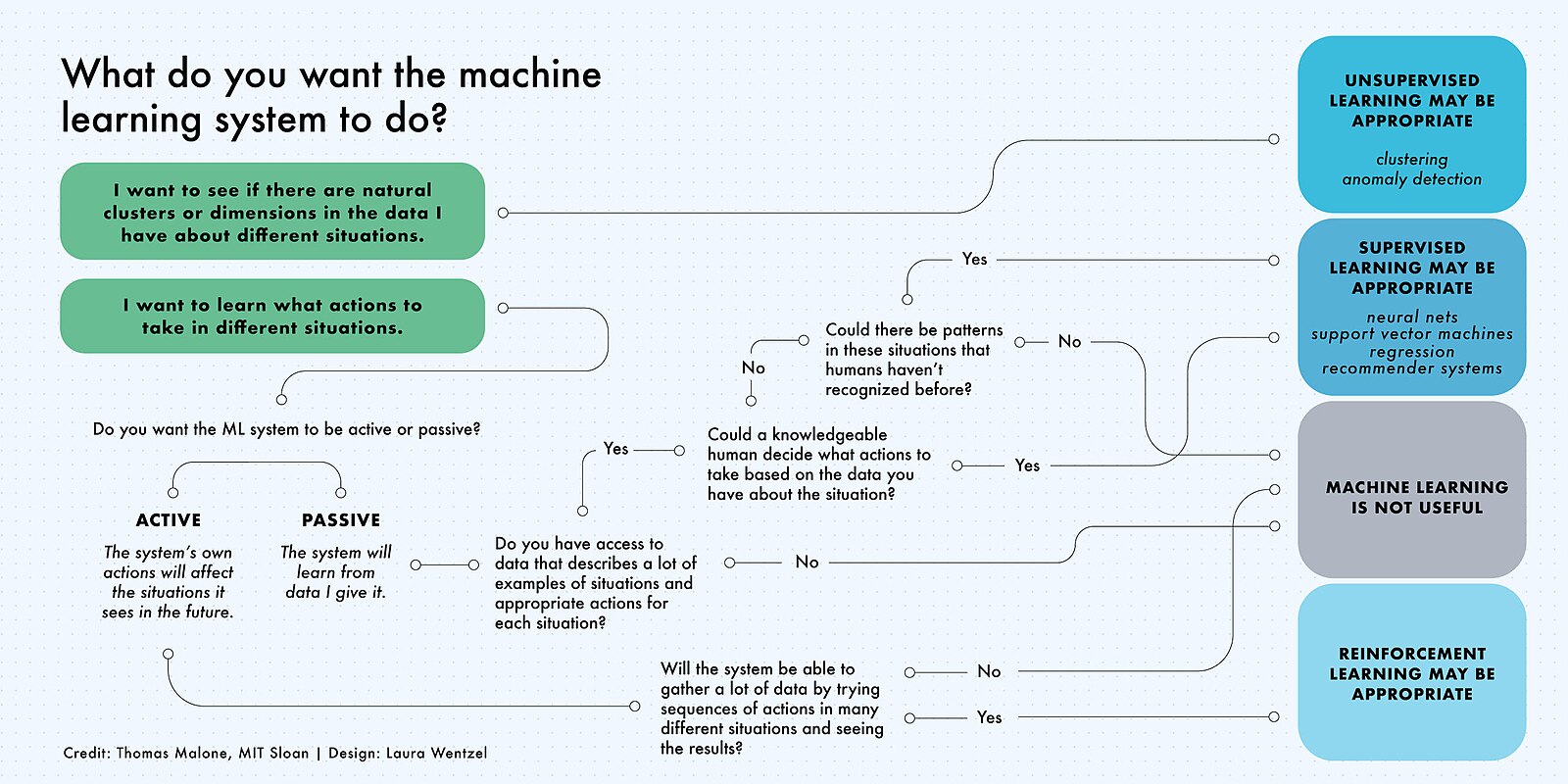
Now we shall talk about the three subcategories of machine learning.
Supervised machine learning models are trained with labelled data sets, which allow the models to learn and grow more accurate over time. For example, autonomous cars use supervised machine learning models. Humans label hundreds and thousands of pictures with traffic signs, traffic lights, and crosswalks (actually, this is what happened a couple years ago when Google captcha had all of those traffic themed ones, those cheeky bastards), and then the model trains on all of the labelled data and would learn ways to identify pictures of dogs on its own. Supervised machine learning is the most common type used today.
In unsupervised machine learning, a program looks for patterns in unlabeled data. Unsupervised machine learning can find patterns or trends that people aren’t explicitly looking for. For example, an unsupervised machine learning program could look through online sales data and identify different types of clients making purchases.
Reinforcement machine learning trains machines through trial and error to take the best action by establishing a reward system. Reinforcement learning can train models to play games or train autonomous vehicles to drive by telling the machine when it makes the right decisions, which helps it learn over time what actions it should take. Imagine a car feeling pain when it turns the wrong way or when it stops at a traffic light and getting imaginary fruits as a reward. This will make it learn over hundreds of attempts.
Now we can talk about three important models that arise from machine learning algorithms: Natural language processing, neural networks, deep learning, and generative models.
Natural language processing is a research area of machine learning in which machines learn to understand natural language as spoken and written by humans, instead of the data and numbers that are normally used by computers. This allows machines to recognize language, understand it, and respond to it, as well as create new text and translate between languages. They work by simplifying the paragraphs of text in the data set to very simple tokens and training on them. Natural language processing enables familiar technology like the infamous ChatGPT, or Siri, or Alexa.
Neural networks are a commonly used, specific class of machine learning algorithms. Artificial neural networks are modelled on the human brain, in which thousands or millions of processing nodes are interconnected and organised into layers. In an artificial neural network, cells, or nodes, are connected, with each cell processing inputs and producing an output that is sent to other neurons. Labelled data moves through the nodes, or cells, with each cell performing a different function. In a neural network trained to identify whether a picture contains a cat or not, the different nodes would assess the information and arrive at an output that indicates whether a picture features a cat or not.
Deep learning networks are neural networks with many layers. The layered network can process extensive amounts of data and determine the “weight” of each link in the network — for example, in an image recognition system, some layers of the neural network might detect individual features of a face, like eyes, nose, or mouth, while another layer would be able to tell whether those features appear in a way that indicates a face or if it is jumbled mess. Deep learning, like neural networks, is modelled on the way the human brain works and powers many machine learning uses.
Generative models use all of the mentioned machine learning algorithms and tricks to create new images based on a set of instructions (like the famous MidJourney or DallE 2). Generative models normally have two different neural networks: a generator network and a discriminator network. The generator network takes a set of random arbitrary images as input and generates an output image from it. The discriminator network takes an image as input and tries to determine whether it is a real image from the training data set or a generated image from the generator network. While training, the generator network tries to fool the discriminator network into thinking the images that it creates are real images. This adversarial process helps the generator network learn to generate more realistic images over time.
In conclusion, machine learning models are really really complicated and this post just barely scratched the indestructible diamond wall and we still are on top of the iceberg. But, the basics of how machines learning models work is actually this and there ain’t much to say on top of all this. As they say: until next time, I’m out.

